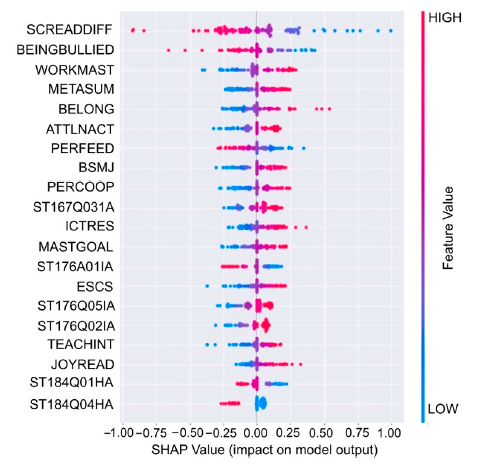
Filipino students ranked last in reading proficiency among all countries/territories in the PISA 2018, with only 19% meeting the minimum (Level 2) standard. It is imperative to understand the range of factors that contribute to low reading proficiency, specifically variables that can be the target of interventions to help students with poor reading proficiency. We used machine learning approaches, specifically binary classification methods, to identify the variables that best predict low (Level 1b and lower) vs. higher (Level 1a or better) reading proficiency using the Philippine PISA data from a nationally representative sample of 15-year-old students. Several binary classification methods were applied, and the best classification model was derived using support vector machines (SVM), with 81.2% average test accuracy. The 20 variables with the highest impact in the model were identified and interpreted using a socioecological perspective of development and learning. These variables included students’ home-related resources and socioeconomic constraints, learning motivation and mindsets, classroom reading experiences with teachers, reading self-beliefs, attitudes, and experiences, and social experiences in the school environment. The results were discussed with reference to the need for a systems perspective to addresses poor proficiency, requiring interconnected interventions that go beyond students’ classroom reading.
Keywords: Machine Learning
@ARTICLE{Cordel2021g,
author={Bernardo, A. B. I. and Cordel, M. O. and Lucas, R. I. G. and Teves, J. M. M. and Yap, S. A. and Chua, U. C.},
title={{Using machine learning approaches to explore non-cognitive variables influencing reading proficiency in English among Filipino learners.}},
journal={{Education Sciences}},
year={2021},
volume={11},
publisher = {{MDPI}}
}