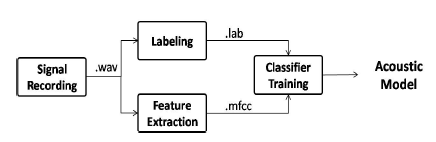
Computer Assisted Pronunciation Training (CAPT) systems aim to provide immediate, individualized feedback to the user on the overall quality of the pronunciation made. In such systems, one must be able to extract features from a waveform and represent words in the vocabulary. This paper presents the performance of Hidden Markov Model (HMM), Support-Vector Machine (SVM) and Multilayer Perceptron (MLP) as automatic speech recognizers for the English digits spoken by Filipino speakers. Speech waveforms are translated into a set of feature vectors using Mel Frequency Cepstrum Coefficients (MFCC). The training set consists of speech samples recorded by native Filipinos who speak English. The HMM-trained model produced a recognition rate of 95.79% compared to 86.33% and 91.66% recognition rates of SVM and MLP, respectively.
Keywords: Signal Classification, music
@ARTICLE{Cordel2020d,
year = 2020,
publisher = {{Asian Research Publishing Network (ARPN)}},
volume = {15},
number = {21},
author = {Cordel, M. O. and Magsino, E. R.},
title = {{Performance comparison of MVDR, MUSIC, and ESPRIT algorithms in signal classification}},
journal = {{ARPN Journal of Engineering and Applied Sciences}},
}